Jun. 23, 2020
If your computer is Cloud, what its Operating System should look like?
By Asher Sterkin @BlackSwan Technologies
Warming Up
Unlike containers, which were still an incremental change introducing smaller VMs with less isolation, the serverless technology brought in truly disruptive tectonic change, yet to be fully absorbed by the software industry. Here, we need to stop talking about faster horses and need to start talking about cars.
While cloud functions (aka AWS Lambda) constitute a crucial ingredient, they are just one piece of a bigger puzzle. To comprehend the whole meaning of the serverless revolution, we have to look at serverless storage, messaging, API, orchestration, access control, and metering services glued together by cloud functions. The cumulative effect of using them all is much stronger than the sum of individual parts. Using the cars vs horses analogy, it’s not only about just the engine, chassis, tires, steering wheel and infotainment taken separately, but rather assembled in one coherent unit.
Approaching such a new technology marvel with the legacy “faster horses” mindset will not do. Disruptive technologies are first and foremost disruptive psychologically. To utilize the full potential of disruption, one has to think anew and act anew.
The problem starts with that all existing mainstream development tools and programming languages were conceived 50 years ago, together with Internet and Unix, when overcoming computing resources scarcity was still the main challenge. Patching new features on the top of that shaky foundation made them fatter, but not more powerful. As such, they all are completely inadequate for the new serverless cloud environment. To make real breakthrough progress, a RADICAL RETHINKING of all familiar concepts is required:
- What is Computer?
- What is an Operating System?
- What is Middleware?
- What is Application?
- What is Programming?
- What is Testing?
- What is Source Code Management?
- What is Productivity?
- What is Quality?
In this article, we will briefly analyze the first two of these topics one by one.
What is a serverless cloud computer?
Over the last decade, the “Data Center as a Computer” concept gradually acquired widespread recognition. When talking about cloud computing, by computer we mean a warehouse-size building filled with tens of thousands of individual boxes, performing various specialized functions and connected by a super-fast local network. If we take a traditional computer model of CPU, ALU, RAM and peripherals connected via BUS, we could say that now dedicated computers perform functions of individual chips and super-fast LAN plays a role of BUS.
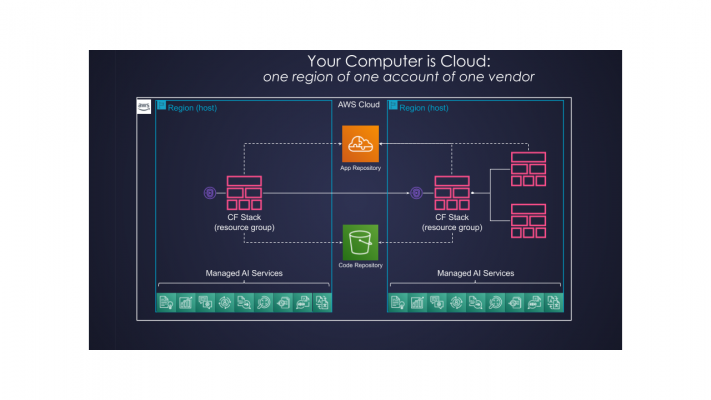
From the serverless computing perspective, however, direct application of this metaphor has limited value. Not only individual data centers are not visible anymore, but the whole concept of Availability Zones also disappears. The minimal unit, we could reason about, is One Region of One Account of One Vendor as illustrated below:
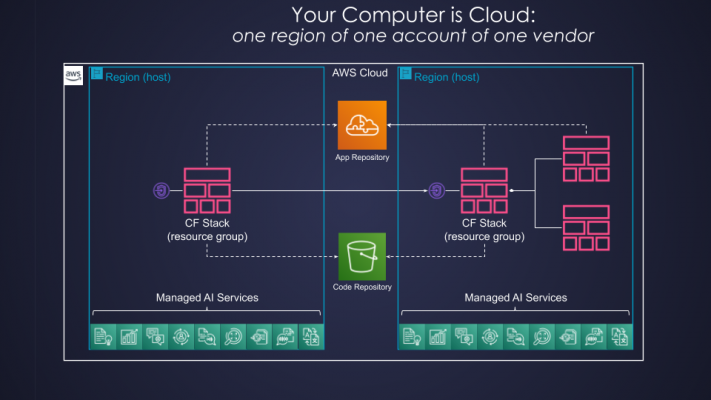
Fig. 1: Serverless Cloud Computer
This is the serverless cloud computer we have at our disposal. Whether it is truly a super-computer or just a very powerful one is sometimes a subject of heated debates. That way or another, serverless cloud computer provides us, for a fraction of cost, with such enormous capacity, we could not even imagine 10 years ago in our wildest dreams.
Could or should we still apply chips/peripherals/bus analogy to this serverless cloud computer, and what would be a benefit of it? Yes, we can, and it’s still a useful metaphor. It is useful especially because it would help us to realize that all that we have now is a kind of machine code level programming environment and that we must raise up the level of abstraction in order to put it into productive usage at scale.
What is a serverless cloud computer ALU?
ALU stands for Arithmetic/Logical Unit — device which in traditional computers performs all basic arithmetic and Boolean logic calculations. Do we have something similar in our serverless cloud computer? Well, in a sense, we do. As with any analogy, it’s good to know where to stop, but we could treat cloud functions (e.g. AWS Lambda) as a sort of ALU device with certain constraints. As of now, any AWS serverless cloud computer in Ireland Region has 3000 of such logical units with 3GB local cache (some people would still call it RAM), 500MB non-volatile memory (aka local disk, split into two halves), 15 minutes hard context switch and approximately 1.5 hour of warmed cache lifespan. These logical devices run “micro-code” written in a variety of mainstream programming languages: Python, JavaScript etc. Whether one is going to use this capacity at full or only partially is another question. The Serverless Cloud Computer pricing model is such that you will pay for only what you use.
Unlike traditional ALUs, there are multiple ways to activate micro-code of such serverless cloud logical devices and to control whether they will perform a pure calculation or will also have some side effects. ALU is just an analogy, but within a limit it appears to be a useful one.
What is a serverless cloud computer CPU?
If we have 3K of serverless cloud ALUs, do we also have CPUs to control them, and do we really need such devices? The answer is there are such devices, but these serverless cloud CPUs, while useful in a very wide range of scenarios, are purely optional. Cloud orchestration services, such as AWS Step Functions, could play such a role with internal Parallel flows playing a role similar to individual cores. An AWS Ireland Region “Cloud CPU” could be occupied for up to 1 year with maximum 25K events. How many of such serverless cloud CPUs could we have? Well, we can get 1300 immediately, and then add by 300 every second. As with cloud functions, we will pay only for what we are using.
What is a serverless cloud computer memory?
Ok, we have ALUs (with some cache and NVM), we have, optional, CPUs to orchestrate them, do we have an analogy for RAM and disk storage? Yes, we do, but we might opt to stop speaking about an artificial separation between volatile and non-volatile memory. Modern CPUs make this separation meaningless anyhow. It’s better just to talk about memory. Serverless cloud computers have different types of memory, each one with its own volume/latency ratio and access patterns. For example, AWS S3 provides support for Key/Value or Heap memory services with virtually unlimited volume and relatively high latency, while DynamoDB provides semantically similar Key/Value and Heap Memory services with medium volume and latency. On the other hand, AWS Athena provides high volume, high latency tabular (SQL) memory services, while AWS Serverless Aurora provides the same tabular (SQL) memory services with medium volume and latency.
Interesting to note, some serverless cloud “memory” services, such as DynamoDB are directly accessible from Step Functions (aka serverless cloud CPUs), while others — only through cloud functions (serverless cloud ALUs). As for now, Step Functions have 32K limit of internal cache memory, and as such are suitable only for direct programming of control flows rather than voluminous data flows. Whether such a limit is a showstopper or a pragmatic trade off choice is a subject for a separate discussion.
A full analysis of available services, which would also include Serverless Cassandra, Cloud Directory and Timestream, is beyond the scope of this memo.
What are serverless cloud computer peripherals?
Ok, we have serverless cloud computer ALUs, CPUs and Memory (yes, yes, all metaphorical, of course), do we have something similar to peripherals in traditional computers? Yes, we do have something similar to ports, which connect our serverless computer to the external world. As with traditional ports, each one supports different protocols and has different price/performance characteristics. For example, AWS API Gateway supports REST and WebSockets protocols, while AWS AppSync supports GraphQL, and AWS ALB supports plain HTTP(s).
Full analysis of available services, which would include CloudFront CDN, IoT Gateway, Kinesis and AMQP, is beyond the scope of this memo.
What is a serverless cloud computer Bus?
So, we have metaphoric ALUs, CPUs, Memory and Ports for our serverless computer. Do we have something similar to Bus, and do we need one? The answer is yes, we do have several types, and we will sometimes need some of them. For example, AWS SQS provides Push high speed, medium volume service, while AWS SNS provides high speed, medium volume Pub/Sub notification service, and AWS Kinesis provides high speed, high volume Push service.
What else does the serverless cloud computer have?
Well, unlike traditional computers, quite a few more batteries are included: data flow unit (aka AWS Glue), machine learning unit (aka Sage Maker endpoint), access control (aka AWS IAM), telemetry (aka AWS Cloud Watch), packaging (aka AWS Cloud Formation), user management (aka AWS Cognito), encryption (AWS KMS), component repository (AWS Serverless Application Repository), and a slew of fully managed AI services such as AWS Comprehend, Rekognition, Textrat, etc.
Complete specification of the Serverless Cloud Computer “hardware” is illustrated below:
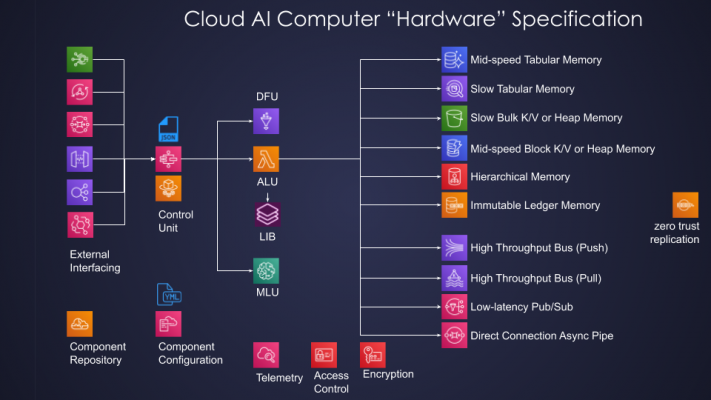
Fig. 2: Serverless Cloud Computer “Hardware”
Serverless Cloud Operating System
Following the good tradition established by E.W. Dijkstra, we will treat the Serverless Cloud Computer metaphorical “hardware” specification outlined above as the bottom layer of a “necklace string of pearls”, namely higher-level, domain-specific virtual machines stacked on the top of lower-level infrastructure virtual machines, as illustrated below:
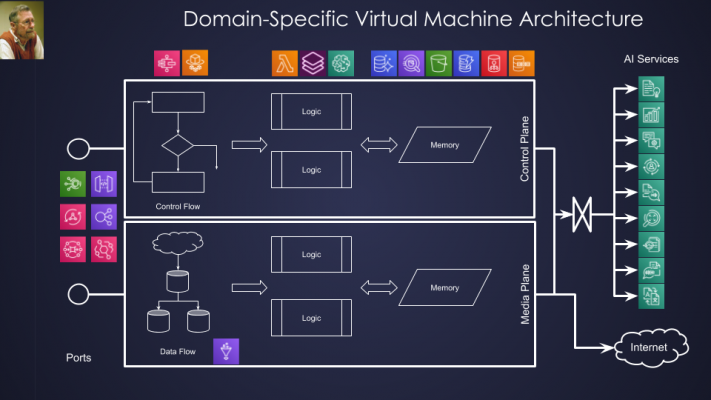
Fig. 3: Domain-Specific Virtual Machine Architecture
The question is what’s next, and how far shall we proceed with such a metaphor?
As it has been mentioned above, the main purpose of this metaphoric description is to highlight how still too low-level abstractions we have at our disposal to tame such a beast.
Following a more or less standard model of software systems layering, the next layer above hardware is usually a Drivers layer, that provides programmatic access to underlying devices. In our case, we could treat cloud vendor SDKs (e.g. AWS boto3) as a “drivers” layer.
With regard to the operating system as well as higher layers responsibilities, there are probably as many opinions as the number of people discussing the subject. In this paper, we are going to adopt a relatively restrictive view on the Operating System as responsible for optimal resource utilization of a single computer, in our case serverless cloud computer.
Indeed, while serverless cloud computers are extremely powerful by common standards, they are not unlimited, and although they could be scaled up, we will always want to get more value for the same amount of bucks. Therefore, optimal resource utilization goal, more formally minimizing the cost while staying within SLA boundaries, does apply.
Optimizing resource utilization of distributed systems and increasing productivity are the responsibility of higher layers, namely Serverless Cloud Middleware and Serverless Cloud Framework, that will be discussed elsewhere in a separate memo.
What kind of resource optimization such Serverless Cloud Operating System should be responsible for? Basically, of two kinds: optimal concurrency structure and optimal packaging. Before we get to optimization details, though, we need to take a brief look at traditional Operating System services, namely: File System, Processes, Installation Packages, and Interprocess Communication.
What is a serverless cloud OS file system?
As we argued above, the whole concept of the file system is probably outdated and for application code development we’d better start talking about cloud versions of traditional data structures such as lists, vectors, sets, hash tables, etc. It could be demonstrated that all these data structures could be efficiently mapped on different serverless cloud memory services mentioned above.
Still, unless we are going to rewrite all available software, which would be impractical, we will sometimes still need to talk about files, for example, Python modules, Linux Shared Objects and Executables. Using local disk storage of cloud functions has to be treated as a special case, mainly for cold start optimization reasons. The ideal solution would utilize Linux File System in User Space — FUSE to mount, depending on price/performance ratio, directly to S3, DynamoDB, Serverless Cassandra or even Serverless Aurora. Unfortunately, that’s not possible today since the FUSE mount requires the Lambda container to run in the privileged mode which is not allowed for security reasons. Another possibility is to develop a cloud version of module importer for each run-time environment: Python, JavaScript, JVM. While it requires some extra work and is less friendly towards legacy code, cloud importer allows some optimizations not available to the traditional disk-based one.
Similar logic applies to Linux Shared Objects and Executables. Ideally, ELF files should be directly loaded from the cloud memory source. That, in turn, would require modifications in the dlopen function — hard to expect in the nearest future. One possible work-around would be to download Shared Library and Executable files from the cloud source to the /tmp folder first. That would bring us back to the 250MB disk space limitation for all Shared Libraries including Python extensions. Another option is to imitate RAM disk, which would double memory consumption subtracted from a larger 3GB budget. As with cloud importer, some non-trivial optimizations to speed up binary files download are possible here.
What is a serverless cloud OS process?
Now, we step into an uncharted territory. Perhaps, a clear analog to the Linux process is yet to be defined. Step Functions running State Machine (even though we have to stop calling them State Machines, which they are not) is a good candidate, but what about individual Lambda Functions triggered by some external event? Shall we treat them as interrupt handlers in traditional Operating Systems? That might be not such a bad idea, but only time will show.
What is a serverless cloud OS installation package?
The answer seems to be obvious — it’s a Cloud Formation Stack on AWS or a similar solution on another cloud platform. In the serverless world, Cloud Formation Stacks do not run — serverless applications have no daemon processes — nothing is running unless explicitly triggered by some external event. In this discussion, we exclude Fargate containers, which do run. Therefore, launching a Cloud Formation Stack just means installing a copy of a Serverless Application. Although it will reserve some resources, it will not consume them until some real workload starts running. Well, almost, storage capacity will still be consumed even in passive mode, but this is not different from disk space occupied by some application even if it has never been started.
What is a serverless cloud OS interprocess communication?
This is another blurry area that requires further elaboration. Traditional Operating Systems, like Linux, have two standard and one semi-standard interprocess communication mechanisms. Shared memory and pipes, named or ephemeral, are two standard interprocess communication mechanisms coming 50 years back to Unix. Tcp/IP is a kind of semi-standard IPC and is mostly devoted to larger scale middleware arrangements.
What is a serverless cloud OS Shared Memory?
All serverless cloud memory services mentioned above are basically shareable. We still need to utilize properly the mutual exclusion and transaction scoping mechanisms available for each one of them. Clojure Persistent Data Structures and Software Transaction Memory supply an interesting source of inspiration.
What are serverless cloud OS pipes?
Unfortunately, we do not have them. More accurately, we do not have good ones. Serverless cloud Bus services enlisted above do a decent job, but for a very limited set of scenarios. Using a biology metaphor, they are good for central veins and arteries, but not for capillaries. As for now, it’s impractical to create a separate SQS queue for each flow — it takes too long to create, and it does not scale well for a large number of flows. If we decide to fun out some processing to a queue, it’s not trivial to figure out when all messages belonging to a particular flow have been processed. Using serverless cloud shared memory facilities it should be possible, in principle, to develop good, lightweight and economical pipes. This is a direction for additional research.
What is serverless cloud networking?
Some interesting research and development activities take place right now in this area (see references).
Optimal Concurrency Structure
Within a typical Serverless Cloud Computer, using AWS as an example, one could identify the following distinct levels of concurrency:
- AWS Step Functions (Cloud CPU)
- Parallel State Machine within a single AWS Step Function (Cloud Core)
- Individual AWS Lambda Function instance (Cloud ALU, normally correlates with #2 above, but not always)
- Linux Process within a single AWS Lambda Function (Cloud ALU Process)
- Posix Thread within a single Linux process within a single AWS Lambda Function (Cloud ALU Thread)
- Coroutine (green thread) within a single Posix Thread of a particular Linux process of a particular AWS Lambda FunctionOptimal concurrency structure depends on several changing factors, mostly data volume, velocity, and external systems (e.g. Web servers) constraints. There is also a question which processes in the system need to be event-driven, and which need to be orchestrated by Step Functions. Finding optimal structure manually would be a daunting task, if possible at all. Finding an optimal structure by applying an appropriate Machine Learning Model fed by operational statistics looks like a much more promising direction, as illustrated below:
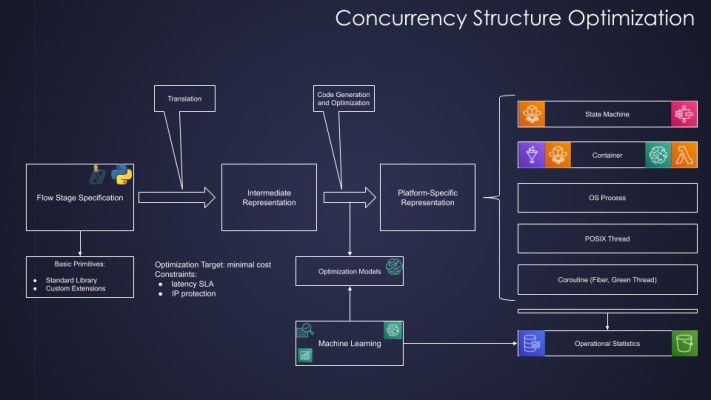
Fig. 4: Concurrency Structure Optimization
This discussion of the optimal concurrency structure reveals another important aspect. Currently available tools for specifying AWS Step Functions, Lambda Functions and Cloud Formation Stacks are at a despairingly low level of abstraction — kind of machine code. Calling these long and ugly JSONs and YAMLs human-readable would be funny if it were not so sad. There is no reason why internal structure could not be treated as a target platform for some high-level compiler. It could be done, and it should be done.
Optimal Packaging
Sticking with the 250MB code size limit of AWS Lambda does not make very much sense. Today, due to this limitation many ML inference processes have to opt for less convenient container packaging even though available 3GB RAM would be more than enough for performing the task. There is no practical reason why Python modules, for example, could not be imported directly from S3. Python importlib allows this in principle. The same logic applies to Linux Shared Objects. While a proper solution would require a deep intervention into AWS Firecracker, which is also not beyond the reach in the future, but less practical for the near term, a close approximation based on additional 250MB of /tmp space is possible today.
But now, we face another problem. Cloud import of, say Python (the same logic applies to JavaScript, Java and .NET), as well as Linux Shared Objects, would increase so-called cold start latency. For many applications, it won’t constitute any issue and overall productivity gains (no need to package zip files anymore) would easily overweight another couple of seconds of delay (free of charge btw). For some other applications, that might be a problem. We, therefore, have another optimization problem: to find an optimal combination of imported modules and shared objects to be placed into an AWS Lambda package (directly or via AWS Lambda Layers) based on a suitable ML model and collected operational statistics.
As with optimal concurrency structure, this is a task for a high-level compiler. We shall treat every case when software engineers are engaged in such yak shaving activity as a complete waste.
Also, notice an emerging pattern here. While traditional operating systems and compilers provided some forms of static optimization, the new Serverless Cloud World requires an optimization process to be dynamic, repeated constantly, and based on collected operational statistics, as illustrated below:
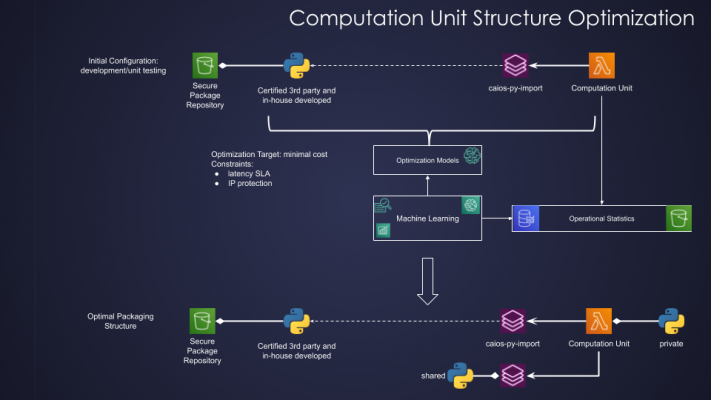
Fig. 5: Computation Unit Structure Optimization
Portable “Hardware” Abstraction Layer
As it usually happens with operating systems, both optimization problems, outlined above, require some form of abstraction insulating core algorithms from technical details of each specific cloud platform. Indeed, 90% of the cloud Python import system depends on the Python module system rather than on how Cloud Storage of AWS vs GCP works. The same logic applies to Linux Shared Objects and concurrency structure. Of course, the same “hardware” abstraction would be useful as a productivity tool for writing portable application code, but here we still have some way to go up to the Framework Layer.
What’s else?
We started from the very basic level of re-considering the serverless cloud computer “hardware” model and outlined major responsibilities of serverless cloud operating system. We still need to talk about the Middleware role in optimizing serverless distributed system resource utilization and about productivity increase through proper adjustments of Framework, including the whole development toolchain. Of course, the real process is not that linear as described. To start even preliminary investigations, we need some minimal development and testing system in place. So, in reality, development activities are conducted at multiple layers in parallel.
Introducing CAIOS
The project, code name CAIOS (stands for Cloud AI Operating System to highlight deep connection with managed AI capabilities), is currently conducted by BST LABS as an internal Open Source Project within the mother BlackSwan Technologies company:

Fig. 6: The CAIOS Project
The main objectives of the CAIOS project are:
- Order of magnitude democratization of the software development process — there is no reason why it should be so complicated, and so painful
- Order of magnitude increase in productivity and quality — there is no reason why software development should be so slow, so expensive, and so buggy
- Order of magnitude increase in value velocity — we must start delivering what customers and market really need rather than what we could push down their throats
- Order of magnitude operational cost reduction — there is no reason why running software systems should be so expensive as it’s today
- Order of magnitude improvements in security — with digitization going to be ubiquitous, tolerating security breaches is not an option anymore
Unleashing and properly utilizing the full potential of the Serverless Cloud Computing provides a unique opportunity to finally implement the right way, the Man-Computer Symbiosis as it was initially envisioned 60 years ago.
Follow us on LinkedIn, Twitter, and Facebook, to be notified about coming news, announcements, and articles.
Corona Post Scriptum
The bulk of this paper was written before the recent Corona Pandemic Global crisis. When I red the Steve Blank’s analysis of potential impact of the Global Economy in general and Startups in particular, I took it seriously:
Shutting down the economy for a pandemic has never happened.
…
If your business model today looks the same as it did at the beginning of the month, you’re in denial.
Indeed, for the software industry, the party is probably over. We won’t be able anymore to command a premium for developing sloppy services poorly matched to real user needs, and deliver them chronically late and over-budget just because of a vague promise to reach one day the hockey stick growth. Because of pandemic concerns, the need for automation will go up, but the tolerance for inflated operation and development costs, poor quality and security and late delivery will sink down to the earth.
Ironically, our circa March 2020 business models should go almost 50 years back. In his seminal ACM Turing Lecture, E.W. Dijkstra made the following comment:
Nowadays one often encounters an opinion that … programming had been an overpaid profession … perhaps the programmers … have not done so good a job as they should have done. Society is getting dissatisfied with programmers and their products.
The year was 1972 and we, software developers, still earn, at least until now, an order of magnitude more than school teachers. But are we doing a more important job, or at least are we doing it well enough?
Alas, the answer is, probably no, and here is why: most of the engineers employed in the software development industry are still busy with what Simon Wardley sarcastically called yak shaving: moving software components from one place to another, configuring and re-configuring infrastructure and at their spare time writing a piece of code which should not be written in the first place.
As an industry, and as professionals, we are caught largely unprepared for what is going to happen: society needs real automation solutions now. Nobody is interested anymore in our mumbo-jumbo. Ordinary people could never understand it. And if we stop shaving yaks over and over again justifying that by some mystical technology needs, how will we continue earning more than doctors, teachers, social workers or even normal engineers in more traditional areas? Do we know how to formulate business problem solutions in a concise and easy-to-prove-correctness form and to leave the rest to tools to perform an automatic conversion into the correct sequence of zeros and ones?
The time for radical revision of our software development habits is NOW.
While initially the CAIOS project started out of an intellectual curiosity about what will happen if we start treating cloud as a super-computer, it is going now to re-adjust itself to new reality. It will laser focus on delivering practically applicably solutions, enabling dramatic reduction of operational and development costs and ironclad code security. These solutions were needed yesterday, and we do not have time anymore to wait till tomorrow.
More detailed information describing available solutions and future plans will follow. Stay tuned.
Follow us on LinkedIn, Twitter, and Facebook, to be notified about coming news, announcements, and articles.

Asher Sterkin, SVP Engineering at BlackSwan Technologies and General Manager at BST LABS. Software technologist and architect with 40 years of experience in software engineering. Chief Developer of the Cloud AI Operating System (CAIOS) project. Before joining BlackSwan Technologies worked as Distinguished Engineer at the Office of CTO, Cisco Engineering, and VP Technologies at NDS. Specialises in technological, process, and managerial aspects of state-of-the-art software engineering. Author of several patents in software system design. During the last couple of years focuses on building the next generation of serverless cloud computing systems, services, and infrastructure.
References
- S. Wardley, Why the Fuss About Serverless
- S. Wardley, Amazon is eating the software (which is eating the world)
- S. Wardley, Thank you Amazon. Boom! Everything in business will change.
- G. Adzic, Serverless architectures: game-changer or a recycled fad?
- G. Adzic, Designing for the Serverless Age
- T. Wagner, Serverless Networking
- T. Wagner, The Serverless Supercomputer
- Luiz André Barroso Jimmy Clidaras Urs Hölzle, The Datacenter as a Computer: An Introduction to the Design of Warehouse-Scale Machines, Third Edition
- E.W. Dijkstra, Notes on Structured Programming
- E.W. Dijkstra, The Structure of “THE” Multiptogramming System
- J.C.R. Liklider, Man-Computer Symbiosis
- D. Engelbart, Augmenting Human Intellect: A Conceptual Framework
- J.C.R. Licklider, R. W. Taylor, The Computer as a Communication Device
- Steve Blank, How Your Startup Can Survive a Worldwide Pandemic
- E.W. Dijkstra, The Humble Programmer

