Jul. 07, 2020
Serverless Cloud Import System part 1
Part One: Linux FUSE Cloud Storage Mount
By Asher Sterkin @BlackSwan Technologies
Introduction
Python Cloud Importer was developed as a part of the Cloud AI Operating System (CAIOS) project described at a high level in a separate article. Here, we are going to provide a more detailed account of motivation and internal design of this part of the system. This is the first part of a tri-part series organized as follows:
- Part 1: Linux FUSE Cloud Storage Mount — solution for a cloud-based IDE (e.g. AWS Cloud9)
- Part 2: Python Cloud Importer — solution for a serverless environment (e.g. AWS Lambda and Fargate)
- Part 3: Deployment Package Optimization — solution for optimal packaging between cloud function local storage, shared EFS and Cloud Storage
Part 2 and 3 are coming in the following weeks.
Acknowledgements
The major bulk of code was developed and tested by Anna Veber from BST LABS. Alex Ivlev from BST LABS made substantial contributions to Cloud 9 integration with goofys. Etzik Bega from BlackSwan Technologies was the first person on the Earth who realized Cloud Importer potential as an IP protection solution. Piotr Orzeszek performed an initial benchmark of the CAIOS Cloud Importer with heavyweight Open Source ML libraries and implemented the first version of Serverless news article classifier.
Yes, we follow the news
With the recent AWS announcement of supporting a shared file system for Lambda Function, the question of the viability of Cloud Import was immediately raised.
Does EFS support mean that the S3-based Cloud Importer value proposition is not viable anymore and its development should be decommissioned? The short answer is No.
To understand why we first need to cover the basics, covered in this part, to understand how Python Cloud Importer works (Part 2), and then to realize that the EFS support (Part 3) is just yet another packaging optimization option, sometimes useful, but by no means an ultimate one.
Industry Landscape
The current state of affairs in package management is a messy patchwork accumulated over decades leading to a lot of confusion and inconsistencies. In this section, we will provide a general overview with particular focus on, yet without too much limited to, the Python ecosystem.
What creates a lot of confusion is that package management exists at multiple levels, and this means different things, multiplied by specifics of each programming language and/or run-time environment. Complete coverage would probably take a full book. In this paper, we will briefly describe each of them, hopefully just enough to get a sense of the complete picture.
Operating System (Linux)
Linux-based Operating Systems are normally distributed in a form of ISO image files downloaded from the Operating System main or mirroring websites. Even at this basic level, the confusion starts. Various Linux distributions come with different sets of pre-installed desktops, run-time environments, compilers, and libraries. The range spans from a bare-bones Linux Server (AWS Linux 2) to a complete development environment packed with all kinds of popular goodies (Fedora). In the general case, it might take substantial effort to figure out what exactly is coming with a Linux ISO file.
Installation Packages
Every Operating System has its own installation packages format and repository structure. For example, Ubuntu uses Debian package format while CentOS-based Linux flavors use RPM format compatible with RedHat commercial distribution of Linux. Each Linux flavor will use its own installation utility correspondingly: apt-get on Ubuntu, yum on CentOS-based, and dnf on Fedora.
Binary packages are usually automatically downloaded and installed from a central or partners repository, or directly from a vendor’s website. Less popular packages could be downloaded and installed manually. In extreme cases, that might be just a compressed tar file.
When a distribution package is installed many things normally happen:
- Package dependencies are checked and all missing dependent packages are installed first
- All distribution files are copied to some predefined location, such as /usr/lib
- Symbolic links to the package executable from another predefined location, such /usr/bin, are created
- Automatic start of daemon processes, where appropriate, is configured
- Symbolic links, environment variables or other forms of configuration are established making package source and binary files accessible during the compilation, link and run-time processes (this is an extreme case for languages such as C/C++)
- Automatic compilation of binary extension packages (in the case of Python)
With binary packages the version dependency hell starts. The same software very often exists in multiple versions, for example, Python 2.7, Python 3.7, Python 3.8. In addition, one binary package might depend on one or more other packages with strict or relaxed version constraints.
In general case, it’s very challenging to figure out what is exactly installed, what depends on what, and how many versions are there. Yes, one could always type yum list, but it will seldom tell you the whole story.
Run-time and Programming Language-Specific Packages
Here, we start facing a true “Tower of Babel” disorder: every run-time environment and programming language ecosystem has its own rules of the game with the version dependency hell as probably the only one common denominator.
Here, we will cover C/C++ and Python, each one in a separate sub-section. Covering other programming languages and run-time environments, such as JVM, JavaScript, .NET and others will be the topic of a separate report.
C/C++
Strictly speaking, it does not have any special module distribution infrastructure. Common C/C++ libraries are either installed as binary packages or just downloaded and placed somewhere.
Stand-alone executables seldom cause any serious trouble. If, however, an executable depends on some custom Linux Shared Object (.so) which in turn depends on some other custom Shared object, be prepared for a long and tiring trip down the rabbit hole if something goes wrong.
Python
Python package management is probably one of the messiest and hard to grasp in its full form. Partially, that could be explained by the Python’s unprecedented popularity for a wide spectrum of applications and platforms: from high performance distributed computing to cloud computing, administration automation, Robotics and embedded Internet of Things.
When talking about Python, we need to distinguish between:
- Installation target
- Python environments
- Package specification
- Package format
- Package repository
- Installation tool
Covering each topic, even briefly, would not be possible within the limited scope of this paper. It will suffice to say that the ultimate goal of the CAIOS Cloud Importer is to make all of them completely irrelevant for ordinary users.
Docker
Docker images add another dimension of flexibility and complexity. Briefly, Docker images are a convenient way of packaging various Linux Operating system resources (e.g. files) together.
Docker technology allows using a file system of one Linux flavor, e.g., AWS Linux 2, on the top (through shared kernel) of another Linux kernel, e.g., Ubuntu. In fact, this is a very popular way of preparing the AWS Lambda Function and Lambda Layer binary packages. While it does work, it introduces quite a lot of additional complexity and fragility.
As with Python installation tools, the ultimate goal of the CAIOS Cloud Importer is to render this method completely unnecessary.
Cloud Environment
It’s not obvious for everybody that a cloud environment itself provides additional ways for deploying and accessing software, including C/C++ and Python packages.
Indeed, using AWS as an example, whenever an AWS Lambda Layer is deployed, we have a kind of analog to Dynamically Linked Library of Windows or Shared Object of Linux available for an in-proc-integration, aka language-dependent, integration.
In addition, AWS Lambda Layers could internally invoke Linux sub-processes (we did it and it works), available for out-of-proc integration via local Linux Pipe or any other Linux IPC mechanism.
Whenever an AWS Lambda Function is deployed we have a kind of analog to Linux top-level process installation available for out-of-proc, aka language-independent, integration.
Whenever an AWS Cloud Formation Stack is deployed, we have a kind of analog to Docker container providing some form of namespace for internal AWS Lambda Functions, AWS Lambda Function Layers, and other resources. One could argue that AWS Lambda runs in a lightweight Firecracker container, not Cloud Formation stack. That’s true, but it does not provide adequate namespace management, so we will stick with analogy.
When an AWS Serverless Application Model (SAM) Template is deployed at AWS Serverless Application Repository we have an analog to Linux Distribution (e.g. Deb or Rpm) repository suitable for local installation and launch.
Finally, AWS Simple Storage Service (S3) provides a kind of cloud-scale distributed file system, which could be accessed via command line, AWS SDK, or special utilities such as goofys.
Finally, when dealing with a Cloud Virtual Machine Image, for example that of AWS Cloud 9 we may meet a mixture of all ingredients mentioned above: something installed directly from an Operating System ISO file, some additional binary packages installed, some Python libraries installed, some Docker images downloaded. If you want to get rid of some of them, replace with newer versions or replace with an alternative, it might be far from trivial and dangerous.
How did it all start?
In the previous article, some basic principles of treating each individual region of one account of one vendor as a separate Cloud Computer and setting the strategic goal of providing an adequate development environment, suitable for ordinary people, in order to unleash the true power of the Serverless technology disruption. And then, our next question was: “how do we start?”
We need to somehow get access to 3rd party Open Source libraries and tools and we need someplace to put my stuff there. What shall we do?
Initially, we tried to follow a more traditional route of working with Python venv, using Docker in order to build correctly zip files for Lambda Layers and Lambda Functions. To a certain degree, it worked, but it was slow, cumbersome, and “democratic” would be the last word to categorize that process.
Then, we started exploring all kinds of proposed solutions for the Serverless Python repository. All of them looked more like quick lift-and-shifts than a fundamental revision of the whole approach. We decided to dig deeper.
And then a moment of epiphany came. What do we really need except for Cloud Storage? Why can’t we just import needed libraries from there and put our stuff there as well? No pip install to run by everybody, no Dockers, no zips. Plane and simple. Yes, somebody will need to put 3rd party libraries on Cloud Storage, but this a one-time activity. After that, everybody else will just need to write import xyz and that’s it. Conceptually, this is similar to the Anaconda Distributions but without the need to actually download and install anything.
CAIOS Cloud Shelf
Could we have such a kind of Cloud Shelf with the “put by one, use by everybody” operational concept? The answer is yes and at two, mutually complementing, levels: Cloud Storage mount and custom Cloud Importer. In this article, we will describe the Cloud Storage mount solution. Python Cloud Importer will be described in Part 2.
Linux FUSE Cloud Storage Mount
All curated packages are uploaded to S3 once for the whole organization or consortia. On the client-side, an S3 bucket is mounted to a local folder and this local folder is included in the PYTHONPATH environment variable. After that, all uploaded files will be available to Python through the standard import mechanism.
For the traditional local desktop or laptop development, such a solution would most likely be of more theoretical than practical value since remote access to cloud storage would incur an unacceptable delay. Things change dramatically, however, if we switch to a cloud-based development environment such as AWS Cloud-9.
Even before the COVID-19 Pandemic, remote work started gaining increasing popularity. With the most recent Shelter-in-place policy, this turned to be a question of survival for many businesses. But working remotely does not come for free, it brings with it new general security and Intellectual Protection concerns to be addressed. Switching to a complete cloud-based development environment such as AWS Cloud-9 addresses many of these concerns.
Now, our S3-mounted access to curated libraries starts flourishing:
- It is fast enough and does not incur any significant latency penalty
- It allows having a fine-grained access control to different libraries
- It is not limited to Python, but rather is equally applicable to any language, run-time environment, data, and executable
After some preliminary investigation, we settled on using the Linux FUSE mount with the goofys utility.
The goofys Mount solution is schematically illustrated in a diagram below:
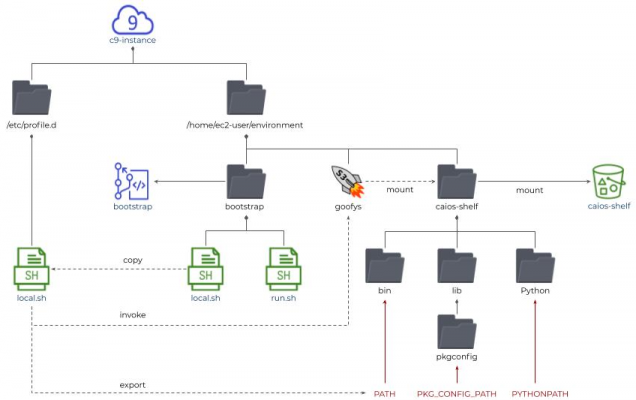
Fig 1: Cloud 9 with goofys Mount Solution
The actual implementation is a bit more complicated, but the overall idea remains the same:
- We connect AWS Cloud 9 environment to an AWS CodeCommit bootstrap repository, which is thus automatically cloned into the Cloud 9 environment file system
- After the Cloud 9 environment is up and running, we invoke the bootstrap/run.sh script to download the goofys daemon executable, to copy the local.sh script file to the /etc/profile.d folder and to invoke sudo reboot
- Now, at every boot of Cloud 9 environment, the /etc/profile.d/local.sh will be automatically executed. It will establish the goofys mount connection between some local folder to some AWS S3 bucket and will adjust PATH, PKG_CONFIG_PATH, and PYTHONPATH environment variables accordingly
- After that, not only Python modules could be imported from the S3 bucket, but also Linux executables (aka tools) could be invoked directly and Linux shared libraries could be built up correctly
This is by itself a remarkable accomplishment, but we want more. We also want the same mechanism to be available in the AWS serverless modules, namely AWS Lambda and AWS Fargate (Kubernetes included). Initially, the main reason for looking for a Cloud Import solution was a need to overcome the AWS Lambda disk space 250MB limitations and to be able to use Machine Learning libraries for serverless inference. Eventually, we found additional advantages of such an approach such as simplified deployment procedures and Intellectual Property protection (to be covered in a separate article).
Could we use the same FUSE Mount in AWS Lambda and containers? Unfortunately, the answer is No.
This is because Linux FUSE requires containers to run in a privileged mode and this is unacceptable from a security point of view. So, we need to embark on developing a custom Python Importer which is covered in Part 2 of this series.
Follow us on LinkedIn, Twitter, and Facebook, to be notified about coming news, announcements, and articles.


