Jul. 21, 2020
Serverless Cloud Import System part 3
Part Three: Supporting shared EFS
By Asher Sterkin @BlackSwan Technologies
Introduction
Python Cloud Importer was developed as a part of the Cloud AI Operating System (CAIOS) project described at a high level in a separate article. Here, we are going to provide a more detailed account of motivation and internal design of this part of the system. This is the second part of a tri-part series organized as follows:
- Part 1: Linux FUSE Cloud Storage Mount — solution for a cloud-based IDE (e.g. AWS Cloud9)
- Part 2: Python Cloud Importer — solution for a serverless environment (e.g. AWS Lambda and Fargate)
- Part 3: Deployment Package Optimization — solution for optimal packaging between cloud function local storage, shared EFS and Cloud Storage
Context and Problem Statement
With the recent AWS announcement of supporting a shared file system for Lambda Function, the question of viability of S3-backed Cloud Import raises up. Indeed,
- The shared file system is faster
- It is 100% compatible with existing solutions and does not require any language-specific import system adaptations
- It is not limited to Lambda Functions and could be shared with Fargate containers and plain EC2 VMs
- Arguments about extra complexity and potential problems with cross-account sharing would not go too far — shared file system might still be a preferable solution because of legacy code considerations
- Even the extra cost (S3 is way cheaper) consideration, might not go too far
To put it short, the AWS support of shared EFS for Lambda Function undermines the S3-based Cloud Importer position as a unique practical way of implementing Serverless Inference with Open Source ML libraries, which do not fit into the Lambda Function 250MB disk space limitation.
Does it mean that the S3-based Cloud Importer value proposition is not viable anymore and its development should be decommissioned?
A short answer is No. Let’s see why.
Shared EFS is not a Panacea
As it was argued in the CAIOS project position paper we treat AWS storage and database services as different types of Cloud Computer memory, each one with its own price/volume/performance ratio. We also outlined there that, in the general case, optimizing service packaging structure is too complex a task for humans and should be done automatically based on collected operational statistics and data and Machine Learning Models. From that perspective, shared EFS is just yet another memory cache tier to be included in the automatic or semi-automatic optimization process.
To defend such an approach, the following claims could be made:
- While shared EFS is indeed faster, it is more expensive, and might not be justified for any service and any workload.
- Using shared EFS for storing Open Source libraries, pre-trained models, in house developed code and models would require an installation process. This is, in general case, a very cumbersome and fragile process.
- While it’s true that some pain might be alleviated by the recently announced AWS CodeArtifact, the need for installation per shared EFS deployment still remains
- Many Open Source libraries, especially in the Machine Learning category, come with a lot of features, which will never be used in Serverless Inference or ETL pipelines. Keeping them all on EFS as a part of the general package will inflate the cost without any real justification.
- The same could be said about pre-trained models and data. For example, the popular NLP transformers library has about 1800 accompanying pre-trained models. Are we going to keep them all on a shared EFS for just in case? Wouldn’t it be cheaper and more practical to keep them on S3 and to make them available when required?
- Using standard Python importlib implementation would not allow selective importing frequently used files from EFS and keeping the rest, seldom or never used, on S3 (see #3 above).
- The biggest advantage of S3-based Cloud Importer is that it makes a large number of libraries and accompanied files just available through the Python import statement without any prior installation. All potentially useful stuff is just there, fully integrated and without any conflicts (which is too often resolved by using multiple Python Virtual Environments — very sub-optimal solution).
- Another related but a separate point is that S3-based import is far more convenient for rapid development — you just upload your code to S3 and that’s it; deploying EFS or even Lambda local-storage based packaging is a more complicated process and is better to be deferred until your system under development is stable.
- Dumping Open Source libraries on EFS just because we can in fact demonstrate a “lift-and-shift” rather than a cloud-native architecture approach. From experience, we know that while the former might be attractive for initial tries, it sooner or later cracks down under its own weight.
- Last not least, by switching to EFS-only based imports we completely give up on collecting usage statistics, which in a cloud environment is equivalent to the kiss of death.
As an elaboration on, and as an addition to the previously described CAIOS Cloud Importer architecture we propose the following extensions:
- Dynamic package optimization (local Lambda Storage, EFS, S3) based on collected operational statistics
- Static package optimization (local Lambda Storage, EFS, S3) based on static code analysis and actual usage of imported modules
Dynamic Optimization
Initial setup of the system is schematically represented below:
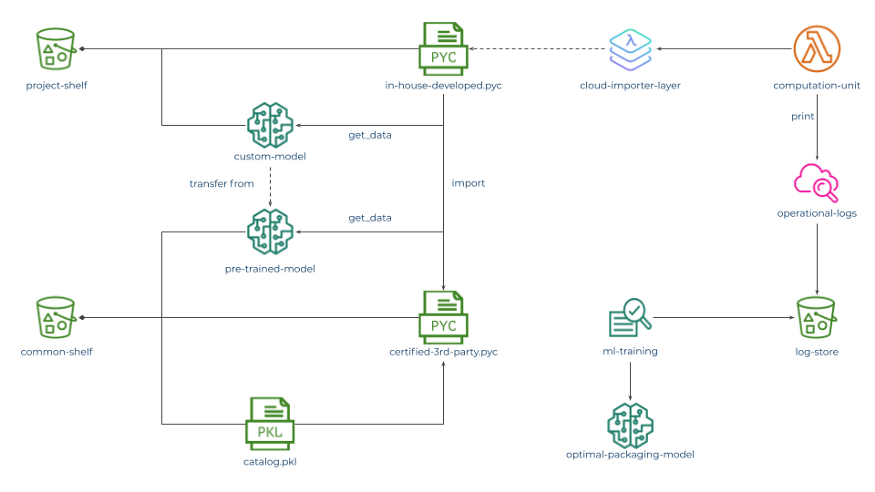
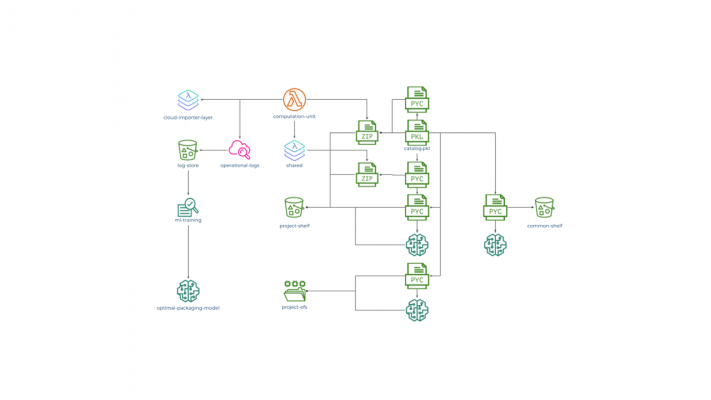
Fig 1: CAIOS Cloud Import Initial Setup
Here, we assume that every computation-unit Lambda function utilizes the cloud-importer-layer Lambda Layer to dynamically import all Python modules, in-house developed and certified 3rd party alike, as well as ML models from S3 tentatively represented as two separate S3 Buckets — one for project-specific and one for general-purpose artefacts.
Operational statistics of this computation-unit are collected by AWS CloudWatch, stored on some storage, collectively represented by an S3 bucket (specific details could vary) and used as an input for an ML training process to build an optimal-packaging-model. Notice, that importing from the common-shelf is presumably already optimized through using a fast access catalogue.
As a result of applying optimal-packaging-model the following general packaging structure is generated (only common patterns are presented, the overall number of combinations is too large):
Fig 2: CAIOS Cloud Import Structure after Dynamic Optimization
Here, we assume the following:
- Fast access catalogue, optimized for every computation unit, is packed in a zip file, stored on the project-shelf S3 bucket, and used by the computation-unit Lambda Function as a starting point
- This access catalog, in the general case, contains references to Python modules located either within the same zip file, within a separate zip file used by a project-specific Lambda Layer (might be convenient for project governance), on the project-shelf S3, on the common-shelf S3 bucket, or on the project-efs.
- The optimization process is driven by trying to narrow latency distribution, skewed by cold start time required for fetching modules and data from S3, while staying within the overall cost constraints allocated for the given computation-unit, as it was initially outlined by Simon Wardley (so-called Worth-Driven Development, and/or FinOps practice)
As we have already stated, performing such optimization manually would be a very complicated, long and error-prone process.
Static Optimization
With all its advantages, the Dynamic Optimization process outlined above might not always be possible or immediately applicable. There are a number of reasons for this, for example:
- It will take time to collect sufficiently representative operational data statistics
- It might take time to develop and tune an appropriate Package Optimization Model to be practically useful (usual gap between initial theoretical breakthrough and production grade system)
- It might turn out that training and re-training Optimization Model will cost more, in terms of resources and operational complexity, than potential gain
- Operational data might not be available in real-time or never because of regulatory constraints
The good news is that the initial version of the same optimization package structure could be obtained by static code analysis of the computation-unit based on discovery which modules and models are imported (retrieved) and which are actually in use. The main point here is that many popular Open Source libraries import a lot of stuff, which will never be used by the particular computation-unit. In such cases, unused modules could be stabbed out or patched to lazy import.
Therefore, the static optimization problem could be presented in a form of well-known Knapsack Optimization, or any other suitable optimization method, and could serve as a starting point for production deployment.
Ability to put some libraries and models on EFS should not be overrated neither completely ignored. It’s strongest selling point is that one could just dump existing code and data on EFS and use them in Lambda without any modifications. But as we know, such a “lift-and-shift” approach could go only so far. There is an operational overhead of properly configuring EFS and guessing its volume, and there is a problem of cost — EFS is expensive. We could specify the optimization problem as follows:
- Suppose, overall storage consumption of imported modules and data by a Lambda function L is X
- Suppose, the maximal latency of this Lambda function L is Y
- If X is <250MB — put all the stuff on local Lambda storage for production deployment (could be easily done on the top of S3-based import which is still unsurpassable for initial development and testing)
- If X is larger than 250MB, but Y is more than cold start of Lambda L, caused by the initial import of modules and fetching data, apply optimization algorithm to move to the local L storage initially imported modules, keep the rest on S3 and perform asynchronous loading of these modules (again, easily doable on the top of S3-based importer)
- If X is larger than 250MB and Y is smaller than cold start of L, even after putting some initial modules on the local L storage, allocate EFS for the difference, and put it there (a more sophisticated, but unsure if justified, approach would be to put on EFS just enough stuff to be able to get the rest from S3 and still stay within the maximal latency constraint — potential cost saving vs extra complexity)
Concluding Remarks
In this part, we demonstrated how, recently announced AWS support for EFS in Lambda Functions could be incorporated into the general CAIOS Cloud Importer model, and two, dynamic and static, package optimization could be implemented in order to get maximal benefit from this important feature. We have not, however, addressed yet, how EFS support in Lambda Functions could be utilized for implementing distributed serverless ETL, inference and training models. These important use cases will be covered in separate publications.
Follow us on LinkedIn, Twitter, and Facebook, to be notified about coming news, announcements, and articles.


